
The technical debate over whether serverless is a subset of Platform as a Service (PaaS) has shifted from a pedantic classification exercise into a high-stakes financial and architectural decision for engineering teams. When cloud architects look at modern infrastructure, the lines are no longer clean.
According to industry tracking data from Datadog’s State of Cloud Report, over 70% of AWS environments now utilize serverless components, while container-driven platforms scale alongside them. This widespread adoption proves that serverless has outgrown its identity as just a sub-feature of traditional application hosting.
The division exists because both technologies target the same core problem, which is removing infrastructure management overhead, while operating under entirely different runtime mechanics. If you audit active engineering forums or read architectural whitepapers, you will find two completely opposing viewpoints argued with equal technical merit.
One side asserts that serverless is simply the logical conclusion of the PaaS philosophy, providing a highly managed runtime environment where the cloud vendor handles the heavy lifting. The opposing camp argues that serverless represents a total paradigm shift because its billing model, event-driven execution structure, and ephemeral lifecycle share almost no operational DNA with traditional, always-on PaaS setups.
To resolve the confusion, you cannot rely on basic marketing definitions. Understanding where these models overlap and where they split requires looking directly at how production workloads run, scale, and cost money in modern cloud ecosystems.
Understanding What PaaS Was Originally Designed to Solve
Before managed cloud platforms became common, development teams were responsible for almost every infrastructure task involved in running applications.
That manual responsibility included provisioning physical or virtual servers, configuring operating systems, maintaining language runtimes, managing complex deployment pipelines, scaling hardware, patching security systems, and continuously monitoring server health.
This created major operational overhead that drained resources, especially for startups and smaller software engineering teams.
Cloud computing PaaS emerged to reduce that structural complexity by shifting the management boundary.
Instead of manually managing raw infrastructure, developers could deploy complete applications directly onto managed platforms where the cloud provider handled the underlying complexities.
The vendor took full charge of operating systems, runtime environments, middleware, deployment tooling, ongoing hardware infrastructure maintenance, and basic scalability support.
This structural shift successfully moved developer focus away from infrastructure operations and directly toward application development.
Popular PaaS platforms established industry standards, including:
- Heroku
- Google App Engine
- Microsoft Azure App Service
- Red Hat OpenShift
At the time of its introduction, PaaS represented a major shift in how cloud applications were deployed, managed, and budgeted.
What Serverless Changed
Serverless computing adopted the exact same infrastructure abstraction philosophy as PaaS but pushed it significantly further down the stack.
With traditional PaaS systems, developers still actively think in terms of application instances, persistent background services, runtime containers, predefined scaling policies, and continuously running application setups.
Even though the underlying infrastructure is abstracted, the deployed applications still behave like long-running, always-on services.
Serverless changed that structural model entirely.
Instead of deploying persistent applications, developers deploy individual functions, event handlers, isolated workloads, and trigger-based execution units.
The cloud provider executes code only when specific events explicitly occur.
That introduced several major architectural changes, which we can look at through the main characteristics defining the modern serverless paradigm:
- Automatic Scaling: The platform instantly handles spikes without manual capacity planning.
- Scale-to-Zero Behavior: Compute resources completely shut down when no traffic is present.
- Event-Driven Execution: Code runs dynamically in response to system triggers rather than waiting on an active loop.
- Execution-Based Billing: Costs are tracked by the millisecond of actual processing time instead of hourly server allocation.
- Ephemeral Runtime Environments: Code executes in short-lived containers that disappear after the request is fulfilled.
This is the exact point where the relationship between serverless and PaaS becomes complicated and divides cloud architects.
Why Many People Say Serverless Is a Subset of PaaS
From a broad, high-level service model perspective, serverless strongly resembles PaaS.
Both models abstract infrastructure management, reduce day-to-day operational overhead, provide fully managed language runtimes, simplify deployment workflows, and allow developers to focus primarily on writing code.
Historically, serverless directly evolved from many of the same core abstraction ideas that originally shaped PaaS.
That is why cloud evolution is often simplified into a linear progression:
Infrastructure as a Service (IaaS)⟶Platform as a Service (PaaS)⟶Serverless Computing
From this linear perspective, serverless looks like a more advanced abstraction layer, a highly managed form of PaaS, or the next stage of complete platform automation.
This specific interpretation is especially common in beginner cloud guides, educational material, simplified architectural diagrams, and high-level cloud computing explanations.
From a conceptual standpoint, the argument makes complete sense because serverless removes even more infrastructure configuration responsibility from developers than traditional PaaS platforms do.
That is why statements claiming serverless extends the PaaS model or that serverless is highly abstracted PaaS remain so common.
These explanations are not technically wrong, they are simply describing the operational relationship entirely from the viewpoint of infrastructure abstraction.
Why Many Cloud Engineers Say Serverless Is Not PaaS
Modern cloud engineers and software architects frequently reject the idea that serverless is merely a subset of PaaS because serverless introduced radical architectural changes that fundamentally altered how applications run.
The systemic differences are not small implementation details or minor marketing adjustments.
They directly affect execution behavior, core application architecture, scaling logic, runtime lifecycles, billing models, and basic workload design.
That is why many enterprise architects formally classify serverless as its own distinct cloud computing paradigm rather than a strict extension of traditional PaaS.
The Biggest Architectural Differences
To fully understand why these two models diverged, we have to examine the core technical areas where their paths split completely.
Continuous Runtime vs Event-Driven Execution
Traditional PaaS applications usually run continuously, maintaining an active state in memory.
Even when user traffic is incredibly low or entirely non-existent, the runtime environment remains active in the background, waiting for incoming requests.
Serverless platforms behave differently.
Functions execute only when triggered by explicit system events, such as:
- Incoming HTTP requests via API gateways
- Real-time database updates or row changes
- Message queue notifications
- File uploads to object storage buckets
- Third-party API calls
- Scheduled cron jobs
Once the specific execution finishes, the runtime container spins down and may disappear entirely from the cluster.
This creates a fundamentally different execution model from traditional application hosting, forcing developers to build applications around ephemeral workflows.
Scaling Behavior
PaaS platforms generally scale by adding full application instances, increasing allocated resources, or following predefined auto-scaling rules based on CPU or memory thresholds.
Scaling in PaaS remains highly configurable, instance-oriented, and often takes minutes to provision new virtual nodes.
Serverless platforms scale automatically and instantly at the individual function level.
Each incoming request or event triggers an independent execution environment without developers manually configuring scaling thresholds or monitoring cluster health.
In real-world production, serverless systems can scale from zero requests to thousands of concurrent executions within seconds, handling massive traffic spikes seamlessly.
That level of granular, instantaneous scaling differs significantly from traditional PaaS infrastructure systems.
Billing Philosophy
The underlying pricing model represents another major architectural distinction that alters how companies budget software operations.
Traditional PaaS platforms usually charge for active instances, allocated compute metrics, and continuously running environments.
Applications hosted on PaaS continue generating steady infrastructure costs even while sitting completely idle in the middle of the night.
Serverless platforms generally charge based on invocation count, exact execution duration, and consumed compute resources measured in gigabyte-seconds during active runtime.
If functions are not actively executing code, infrastructure costs drop directly to zero.
This philosophy changed how modern organizations approach cloud cost optimization, shifting the focus toward pure consumption-based efficiency.
Stateful vs Stateless Design
Traditional PaaS environments commonly support long-running user sessions, persistent local memory states, continuously available background services, and complex stateful applications.
Serverless systems are fundamentally optimized for stateless execution, short-lived workloads, isolated function runs, and ephemeral processing tasks.
Persistent state cannot be safely stored in the local serverless container memory because that container can be destroyed immediately after execution.
Instead, state must be managed externally using decoupled cloud services:
- Relational and non-relational databases
- Cloud object storage systems
- Distributed caching layers
- External distributed storage systems
This architectural shift heavily influences how modern cloud-native applications must be written, structured, and debugged.
Why the Confusion Exists
The core confusion persists because engineers compare serverless and PaaS from entirely different technical perspectives.
If you compare them strictly by their abstraction level, serverless resembles an advanced form of PaaS because both hide virtual servers from the developer.
If you compare them by runtime behavior, execution lifecycles, and operational architecture, serverless behaves like a completely distinct cloud computing model.
Both analytical perspectives are technically valid in their own context.
The ongoing disagreement is mostly a matter of classification philosophy rather than a factual contradiction over how the code actually runs.
Function as a Service (FaaS) Makes the Distinction Even More Important
The rise of Function as a Service, or FaaS, pushed serverless even further away from traditional PaaS concepts.
Major cloud infrastructure options introduced execution models centered around isolated functions, event-driven execution, ephemeral compute, automatic scaling, and stateless processing:
- Amazon Web Services Lambda: The pioneering FaaS platform featuring deep integration across the cloud ecosystem.
- Google Cloud Functions: An event-driven platform optimized for lightweight microservices and data pipelines.
- Microsoft Azure Functions: A highly scalable framework featuring advanced orchestration capabilities like Durable Functions.
These specialized environments no longer resembled traditional web application hosting platforms.
As a result, serverless gradually evolved into its own highly technical operational category within modern enterprise cloud computing.
Real-World Examples of Serverless vs. PaaS in Production
Examining how engineering teams deploy these systems in production highlights the practical differences between both choices.
Media Processing Pipelines
A digital media enterprise needs to process user uploaded videos, generating multiple resolutions and thumbnail images. This workload is highly unpredictable and resource intensive.
Using a serverless approach with AWS Lambda or Google Cloud Functions is highly effective here. The system sits at zero cost until a user uploads a video file to an object storage bucket. This event triggers hundreds of parallel functions to process the video segments simultaneously, scaling back down to zero the moment the processing pipeline empties.
Enterprise Monolithic Portals
An established financial firm operates an internal dashboard application used by staff during standard business hours. The application features extensive reporting modules, relies heavily on complex local memory caching, and connects to a traditional SQL database cluster.
Deploying this stack onto a traditional PaaS like Heroku or AWS Elastic Beanstalk is the most logical choice. The predictable traffic profile means the application instances can remain powered on and warm, avoiding latency issues from cold starts. The persistent runtime allows the system to easily maintain its database connection pools and local memory caches without complex workarounds.
Event-Driven Automation and Cron Tasks
An e-commerce platform needs to run a database cleanup and inventory reconciliation script every night at midnight. The script runs for forty seconds, updates inventory counts, and then terminates.
| Metric | Serverless Approach (e.g., AWS Lambda) | PaaS Approach (e.g., Persistent Dyno) |
| Active Compute Time | 40 seconds per day | 24 hours per day |
| Idle Resource Cost | Zero | Continuous provisioned rate |
| Operational Effort | Event triggered trigger config | Scheduled daemon process maintenance |
Running this task on a serverless platform means the company pays only for forty seconds of compute resources per day. Utilizing a traditional PaaS would require paying for an active application instance that sits completely idle for over twenty-three hours a day, demonstrating the clear economic advantages of consumption based infrastructure for transient workloads.
The Hidden Limitations of Serverless Architecture
While serverless technology offers impressive capabilities, it introduces unique technical tradeoffs and architectural challenges that engineering teams must evaluate carefully.
The most prominent operational challenge is the cold start phenomenon. When a serverless function has not been executed recently, or when the platform needs to scale out to handle a sudden traffic spike, it must provision a new microVM container from scratch. This initialization process introduces noticeable latency, often adding hundreds of milliseconds to the initial request’s response time, which can degrade the end user experience for interactive applications.
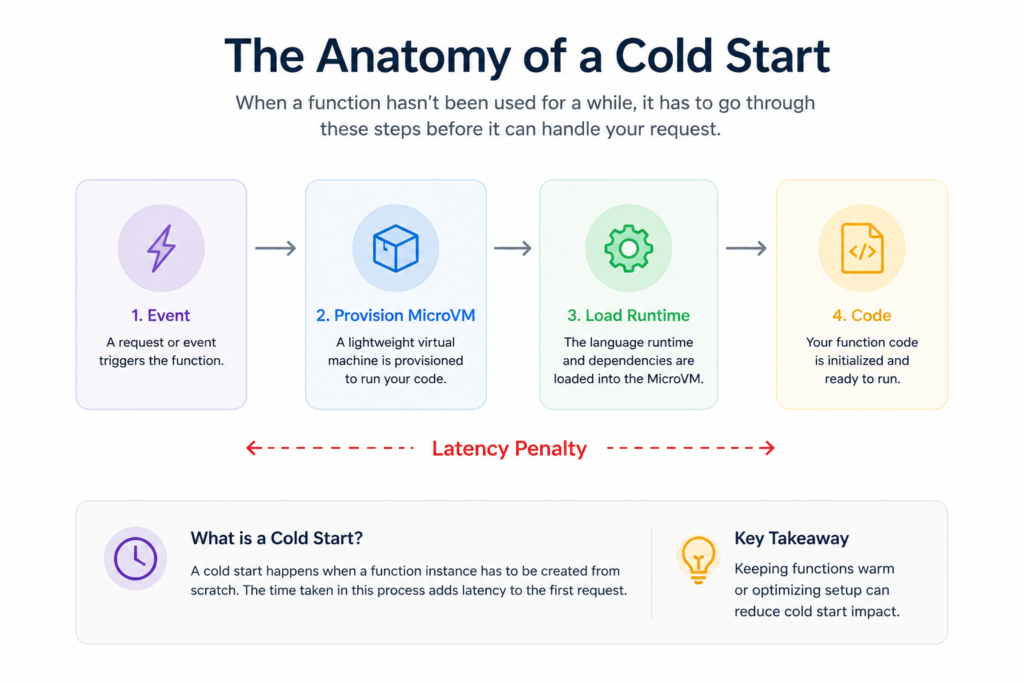
Debugging and operational observability also become significantly more complex in a highly distributed serverless ecosystem. Because execution environments are transient and short-lived, engineers cannot simply log into a server instance to inspect active processes or review local log files.
Tracking down an application error requires setting up advanced distributed tracing systems, structured cloud logging frameworks, and external observability platforms to reconstruct the sequence of events across dozens of independent functions.
Vendor lock in remains another serious long-term risk. Unlike containerized software that runs smoothly on any basic virtual machine, serverless functions are often tightly coupled to their specific cloud provider’s proprietary APIs, identity systems, and event fabrics.
Migrating a complex, event driven application from AWS Lambda to Google Cloud Functions or Azure Functions frequently requires a comprehensive rewrite of the infrastructure code and system integration layers.
Cost Comparison Between Serverless and PaaS
Evaluating the financial economics of serverless versus Platform as a Service requires analyzing how your specific application’s traffic profile interacts with cloud billing engines.
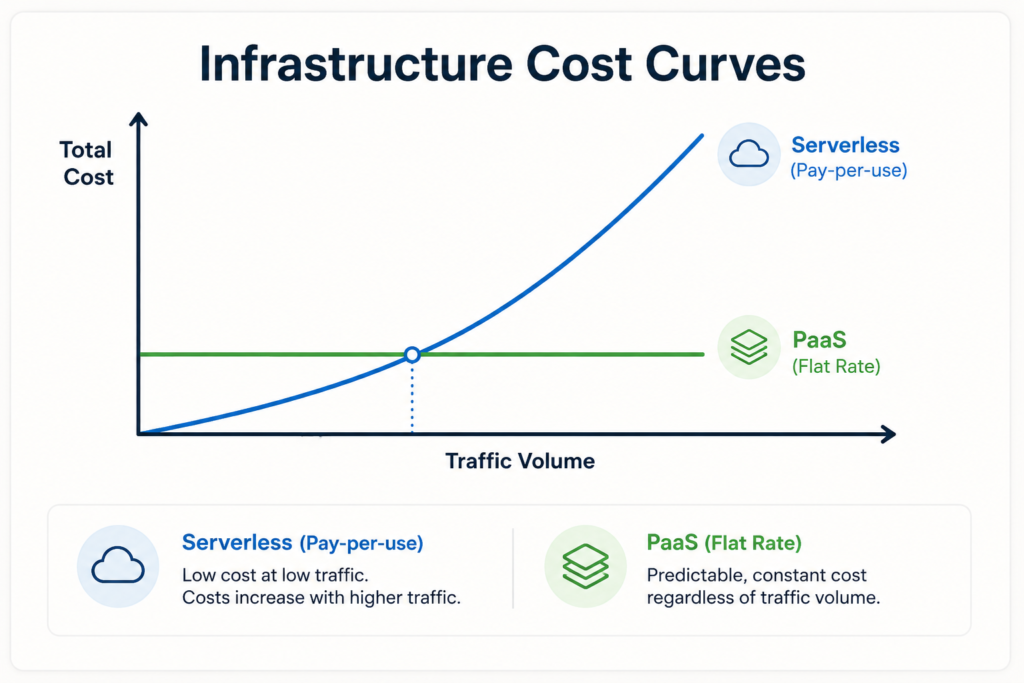
For applications with low, intermittent, or unpredictable traffic profiles, serverless is highly cost effective. Because serverless billing drops to absolute zero when the platform is idle, a microservice that runs only a few hundred times a day will incur a monthly infrastructure bill of just a few cents.
Running that same microservice on a traditional PaaS requires paying for a continuously active compute node, resulting in constant baseline expenses regardless of usage.
However, as traffic patterns scale up and become steady, the financial dynamics invert. Because serverless providers charge a premium for the flexibility of millisecond-level billing and automated scaling, sustained high-volume execution becomes expensive.
A web application processing millions of continuous, predictable requests throughout the day will often cost significantly more on a serverless framework than if it were hosted on dedicated PaaS instances.
The critical decision point for financial optimization centers on resource utilization efficiency. Engineering teams must calculate the ratio between an application’s idle time and its active execution periods. If an application maintains a flat, high volume traffic profile, PaaS delivers predictable, cost effective baseline budgeting. If the workload is erratic, seasonal, or highly distributed, serverless represents the optimal financial path.
Where the “Subset of PaaS” Idea Still Makes Sense
Calling serverless a subset of PaaS still serves a practical purpose in educational explanations, beginner cloud architecture discussions, high-level service model comparisons, and simplified abstraction diagrams.
It helps explain how infrastructure responsibility gradually shifted from internal enterprise developers to public cloud providers over the last two decades.
For high-level teaching purposes and conceptual onboarding, this simplified relationship is highly useful, intuitive, and easy for new developers to understand.
Where That Explanation Becomes Incomplete
In real-world cloud engineering, relying on the subset of PaaS explanation quickly becomes too simplistic and leads to poor architectural decisions.
Modern serverless systems have introduced distributed event architectures, granular auto-scaling patterns, complex function orchestration workflows, highly decoupled microservices, and consumption-based infrastructure economics.
Those core operational characteristics differ significantly from traditional PaaS application hosting environments.
That is why experienced infrastructure architects frequently separate PaaS, Serverless, FaaS, and CaaS (Container as a Service) into completely different operational cloud categories when designing enterprise applications.
The Most Accurate Professional Answer
If an engineer asks whether serverless is a subset of PaaS, the most accurate answer requires balancing historical context with modern architectural reality.
Serverless originated from the exact same infrastructure abstraction philosophy as PaaS and is frequently described as an evolution of the PaaS model.
However, modern serverless computing introduced fundamentally different execution behavior, instantaneous scaling dynamics, sub-second pricing structures, and stateless architectural characteristics.
This is why the vast majority of cloud engineers, system architects, and technical writers now treat serverless as a separate cloud computing paradigm rather than a strict subset of PaaS.
That integrated explanation accurately reflects how modern cloud architecture discussions approach the reality of enterprise deployments today.
Frequently Asked Questions
Is serverless technically part of PaaS?
Historically, serverless evolved from many of the same ideas that shaped PaaS. However, modern serverless systems introduced enough architectural differences that many engineers now classify them separately.
Why do some people call serverless an evolution of PaaS?
Both technologies abstract infrastructure management and allow developers to focus mainly on code instead of server administration. Serverless simply pushes that abstraction much further.
What is the biggest difference between serverless and PaaS?
The biggest difference is execution behavior. Traditional PaaS platforms usually run continuously, while serverless platforms execute workloads only when triggered by events.
Does serverless completely remove servers?
No. Servers still exist physically. The term “serverless” means developers no longer manage the servers directly.
Is AWS Lambda considered PaaS?
Amazon Web Services Lambda is usually classified as a Function as a Service (FaaS) platform within the broader serverless category rather than a traditional PaaS service.
Why is serverless often cheaper for small workloads?
Because serverless platforms generally charge only for execution time and actual resource usage. When functions are idle, infrastructure costs can drop close to zero.




